



...
testsuites.DriverInfo{
Name: "csi-nfsplugin",
MaxFileSize: testpatterns.FileSizeLarge,
SupportedFsType: sets.NewString(
"",
),
Capabilities: map[testsuites.Capability]bool{
testsuites.CapPersistence: true,
testsuites.CapExec: true,
},
}
...Kubernetes cluster
Testing Performance and Scalability
Evgenii Frikin
Huawei 
1.0.0
2021-05-30
About me
 Evgenii Frikin | My experience:
|
Agenda
| Introduction Problem Scalability testing Workload testing Solution Overview Compare Deploy Test Measurements Compare of results Experience |
|
Introduction

Introduction
|
Introduction
| One of the most important aspects of Kubernetes is its scalability and performance characteristic. As Kubernetes user, administrator or operator of a cluster we would expect to have some guarantees in those areas What Kubernetes guarantees? — Kubernetes Team |
Introduction
Developers
New features in Kubernetes (e.g Scheduler or API)
Outside of Kubernetes (e.g CNI, CSI or k8s Operator)

Introduction
Administrator/Operator
Performance
Scalability
Stability
Introduction
Architect
Capacity planning
Cost calculation
Scalability architecture
Introduction
|
Introduction
Introduction
Introduction

General problems

General problems
|
General problems
|
General problems
|
General problems
|
Scalability testing problems
Scalability testing problems
Spawning large-clusters is expensive and time-consuming
|

Scalability testing problems
Need to do once for each release Kubernetes or it components
|

Scalability testing problems
Need a light-weight mechanism for fast deploy k8s cluster
|

Workload testing problems

Workload testing problems
Unfriendly for users
|

Workload testing problems
Most components that are developed outside of Kubernetes
|

Workload testing problems

Scalability testing solutions

Scalability testing solutions
|
|
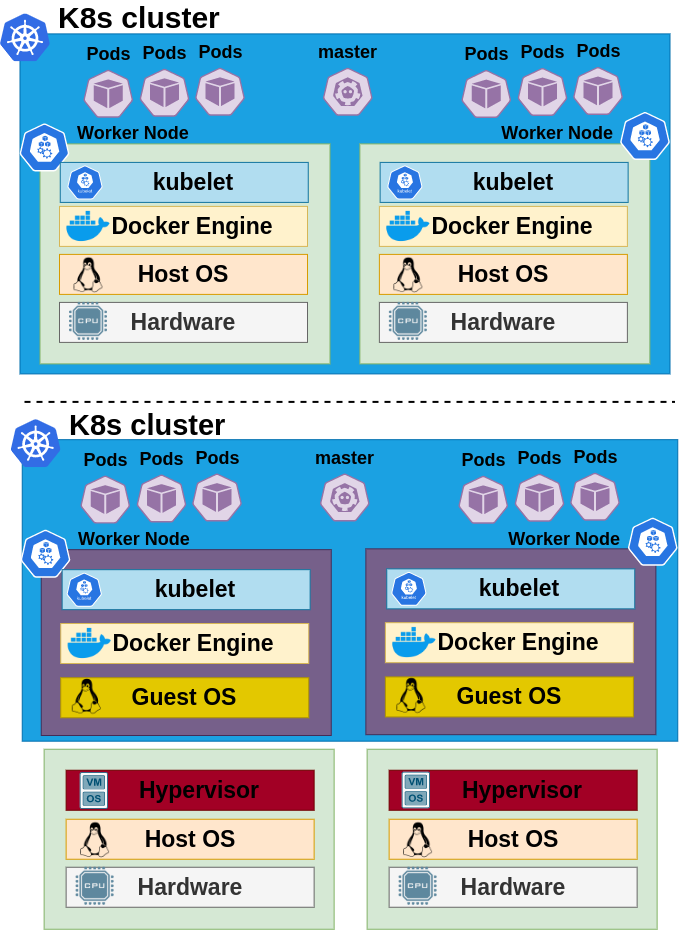
Scalability testing solutions
|
|
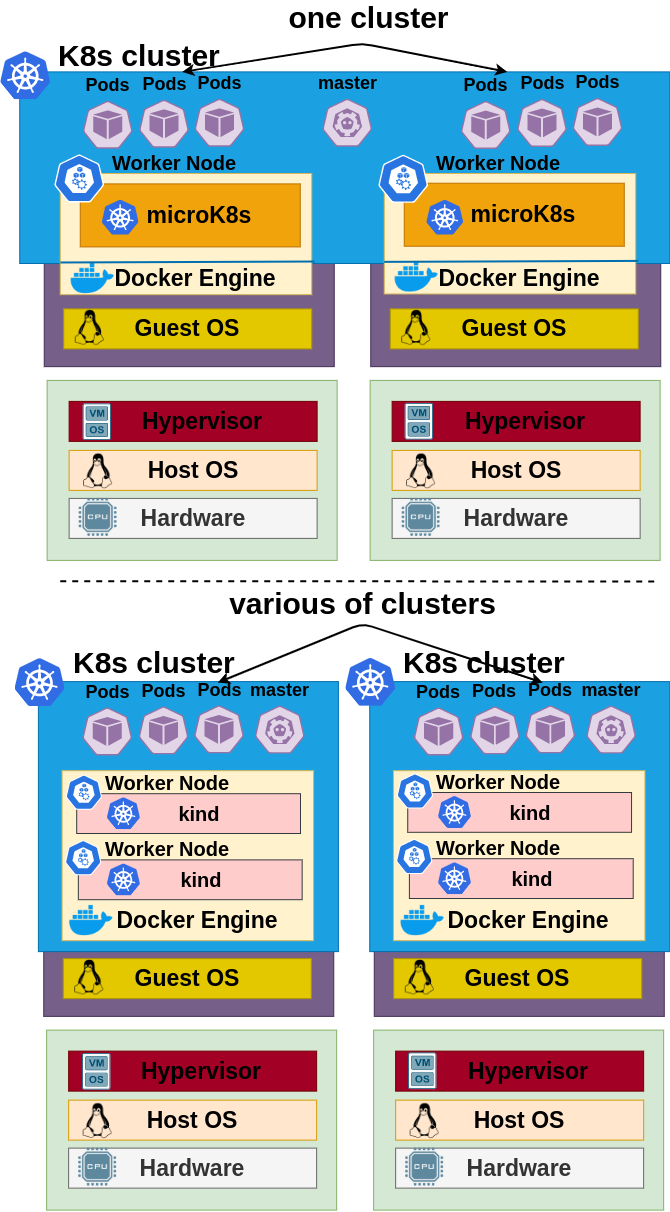
Scalability testing solutions
|
|
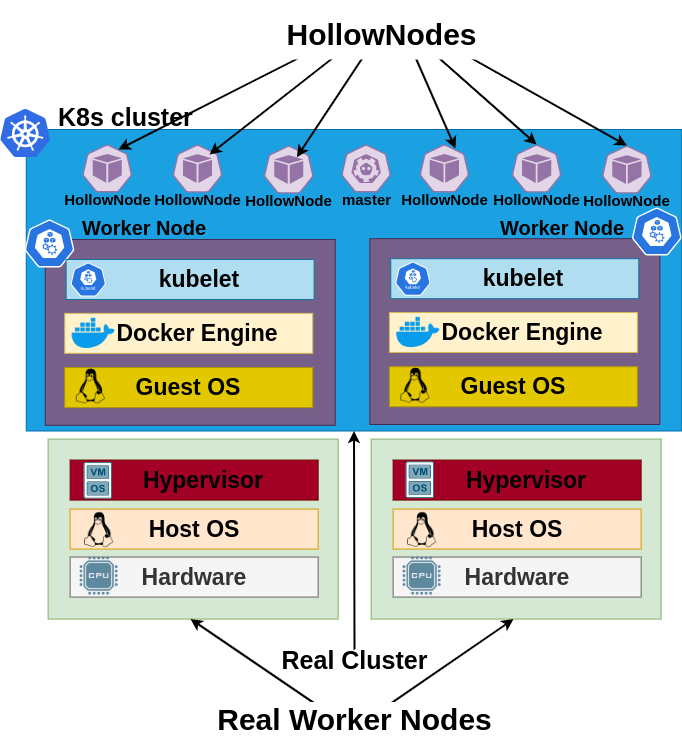

Why kubemark?
Why kubemark?
|
|
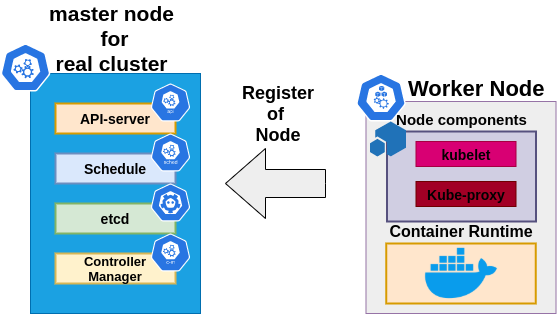
Why kubemark?
|
|
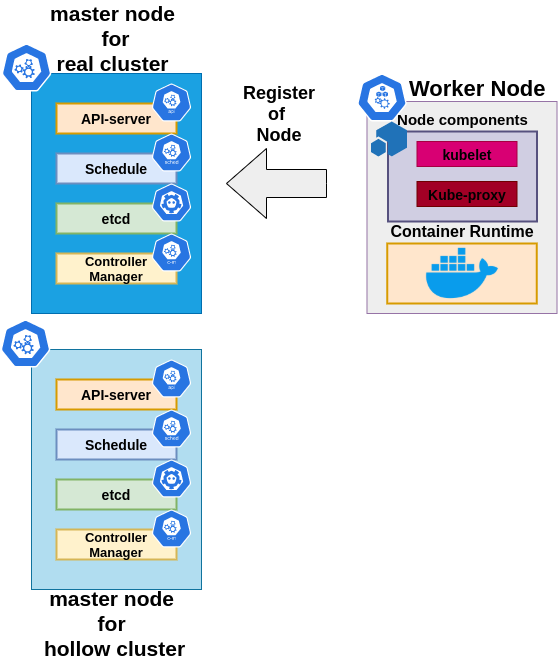
Why kubemark?
|
|
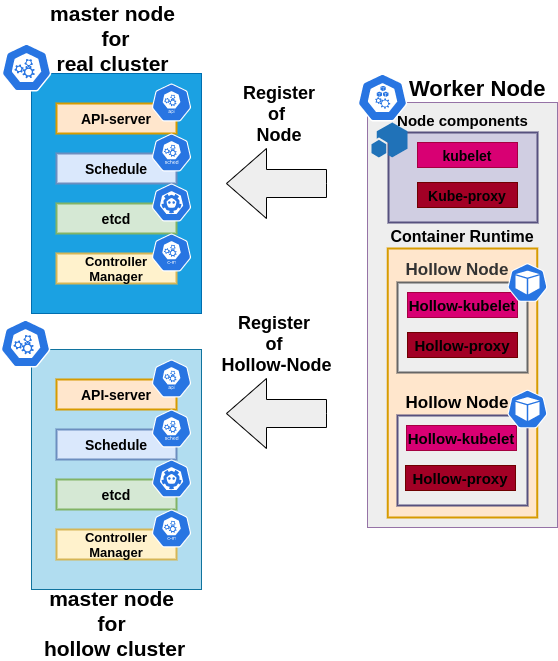
Why kubemark?
Hollow cluster = real cluster
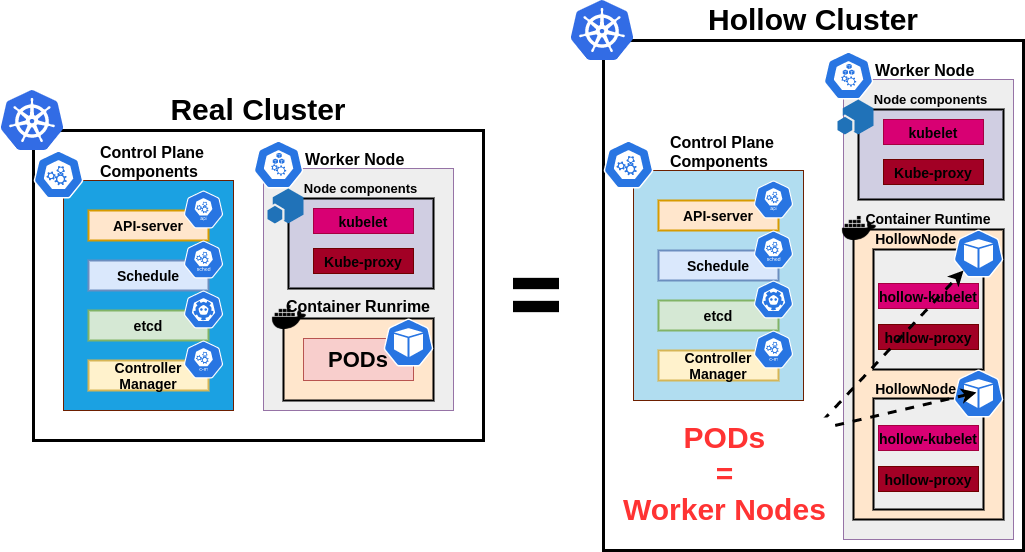
Why kubemark?
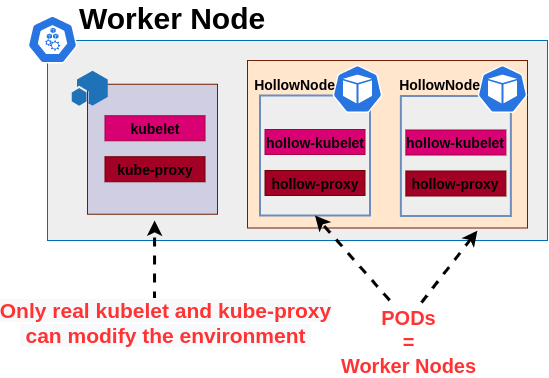
Capability to run many instances on a single host
HollowNode doesn’t modify the environment in which it is run
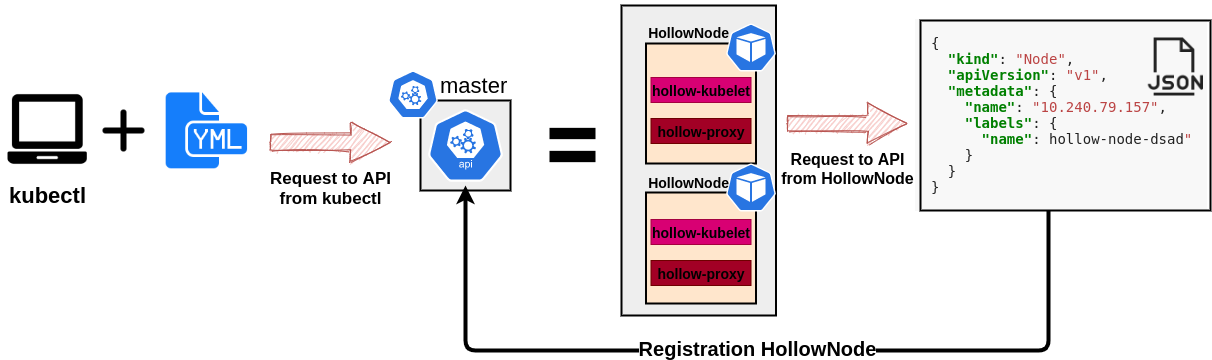
Why kubemark?
Cheap scale tests
~100 HollowNodes per core (~10 millicores and 10MB RAM per pod)
Simulated cluster = Deploy time of a real cluster + Deploy time of HollowNodes
kubectl tool used for all operations scaling operations

Workload testing solutions
helm or kubectl apply -f + some YAML files
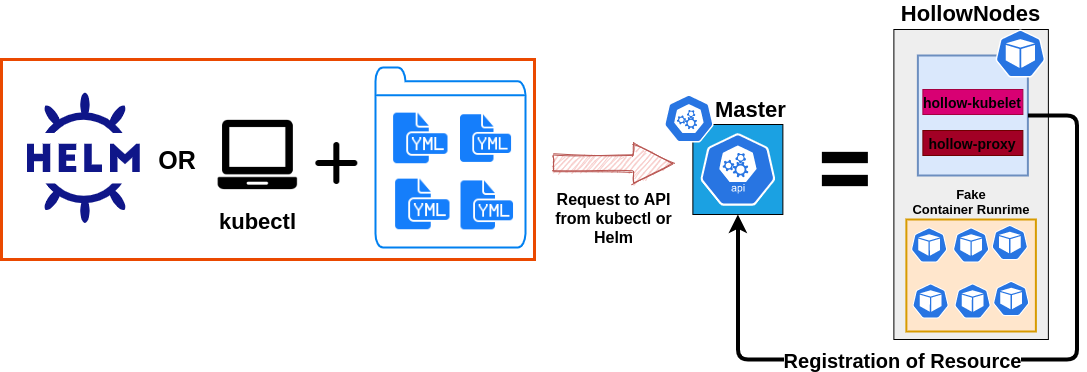
Workload testing solutions
helm or kubectl apply -f + some YAML files
clusterloader2
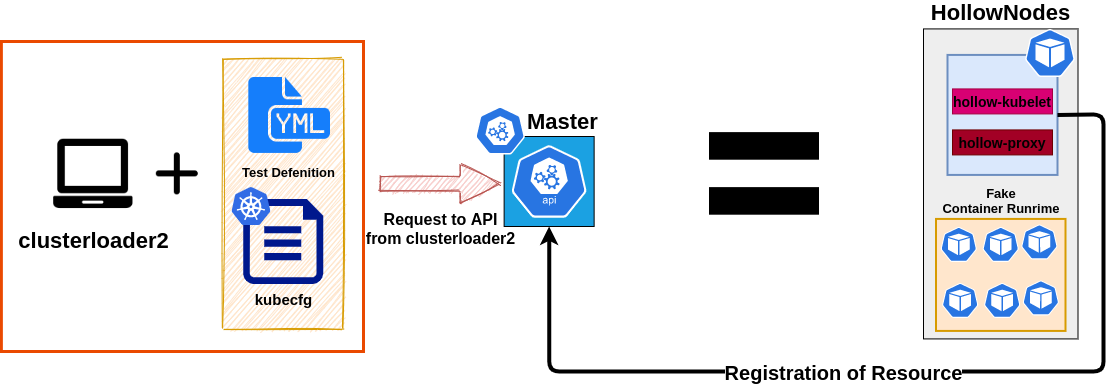
Clusterloader2
Why clusterloader2?
Why clusterloader2?
Simple
Kubeconfig
Definition of sest (YAML)
Providers (gke, kubemark, aws, local, etc)

Why clusterloader2?
User-oriented
No Golang
Easy to understand

Why clusterloader2?
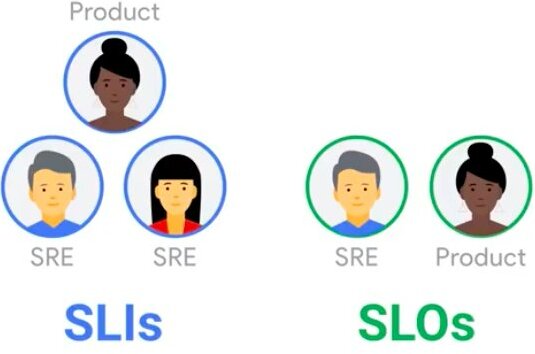
Testable
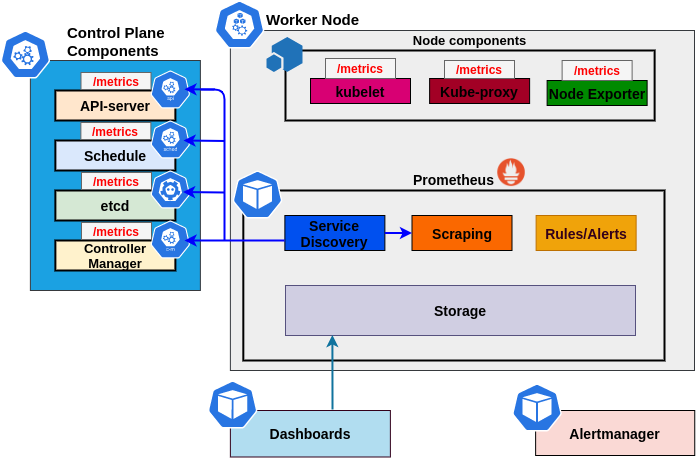
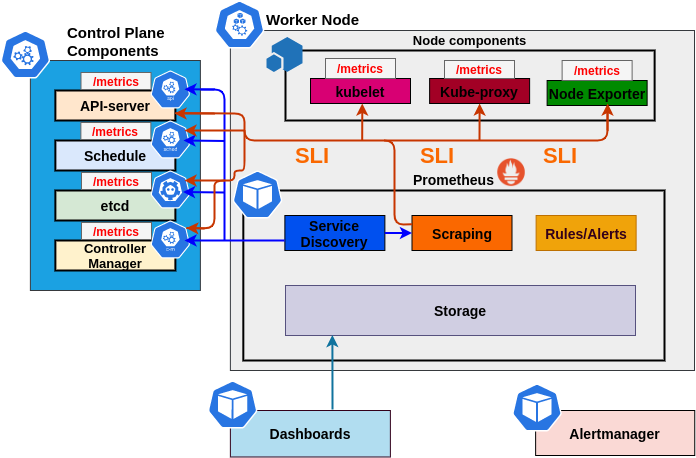
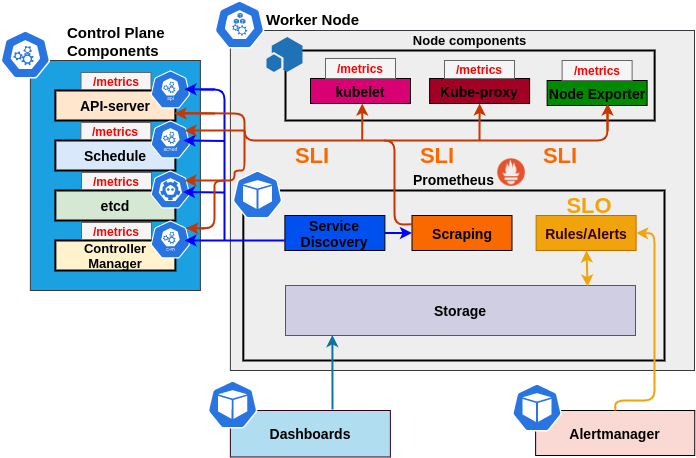
Measurable SLI/SLO
Declarative paradigm
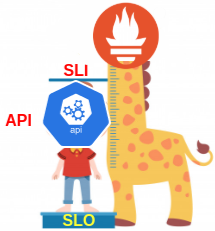
Why clusterloader2?
Extra metrics
PodStartupLatency
MemoryProfile
MetricsForE2E
…

Deploy of hollow cluster

Deploy of hollow cluster
Deploy of hollow cluster
Deploy of hollow cluster
Deploy of hollow cluster
kubectl get nodes -l hollow
 |
clusterloader2 run
clusterloader2 run
clusterloader2 run
Results of clusterloader2 work



Results of measurements for etcd



Results of measurements for API-server




Deploy of large cluster

Deploy of large cluster
Results of clusterloader2 work

Results of measurements for etcd
Results of measurements for API server
Our experience
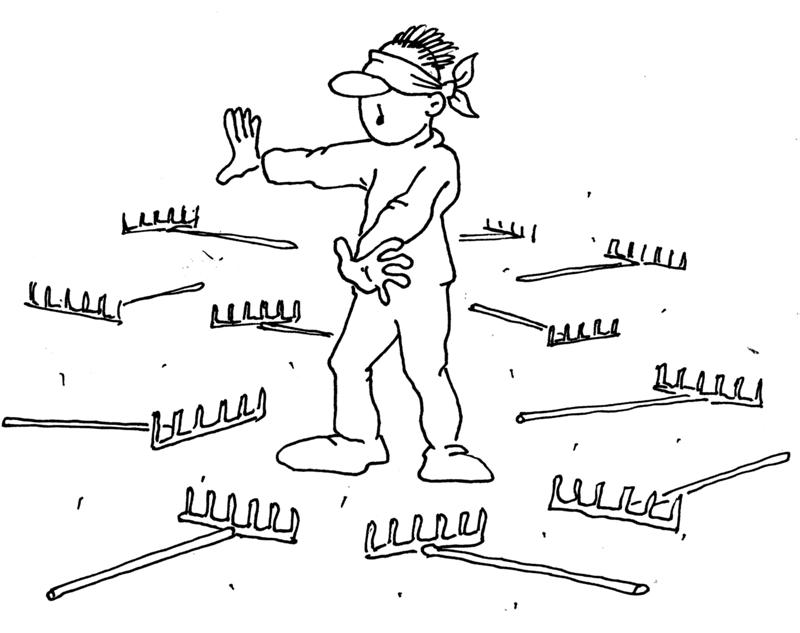
Our experience
Our experience

Scaling k8s cluster up to 18k nodes(k8s v19.7)
Real ~200 worker nodes and 3 master
Workload:
80k out of the box
142k after tuning API-server
Our experience
More than 20 real k8s clusters rendered inoperable during tests
default configuration not suitable for large large scale clusters

etcd
CNI
API-server
memory leaks caused by large number of resources
etcd
API-server
Our experience
Other
|
|

ANY QUESTIONS?

FEEL FREE TO ASK ME

efrikin.github.io/devopsconf2021